59:47
EducationAndrej Karpathy
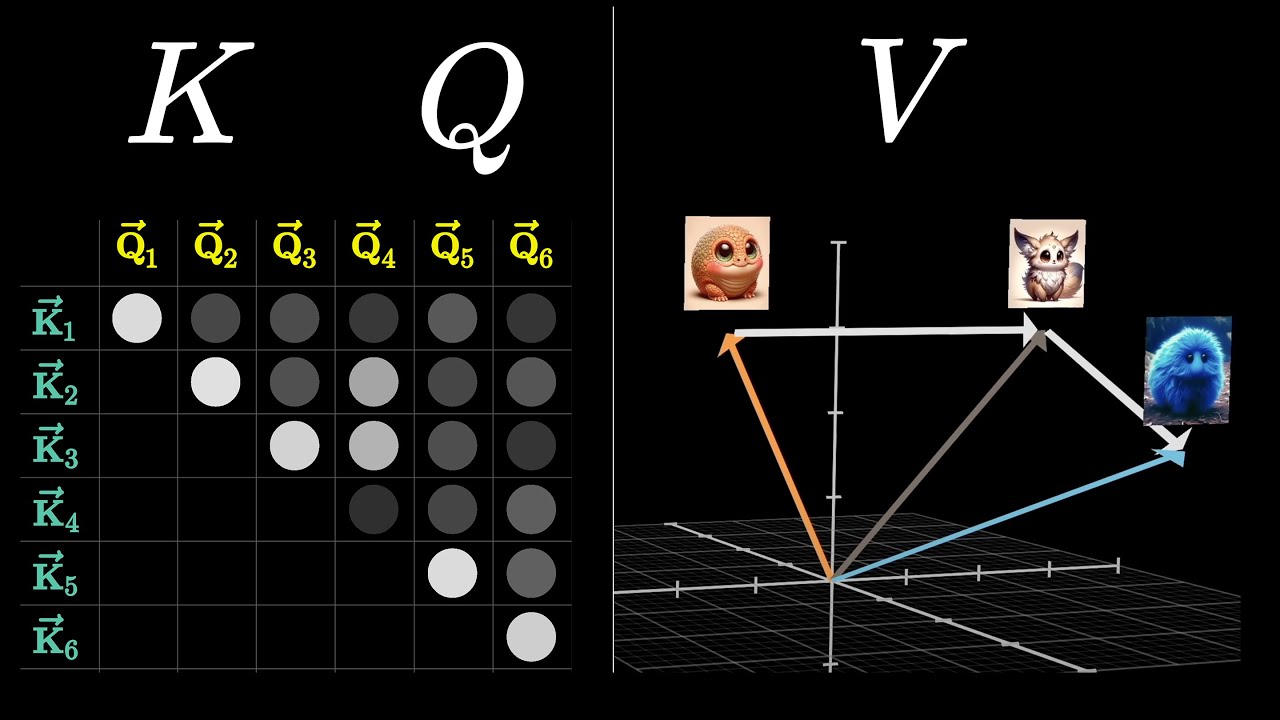
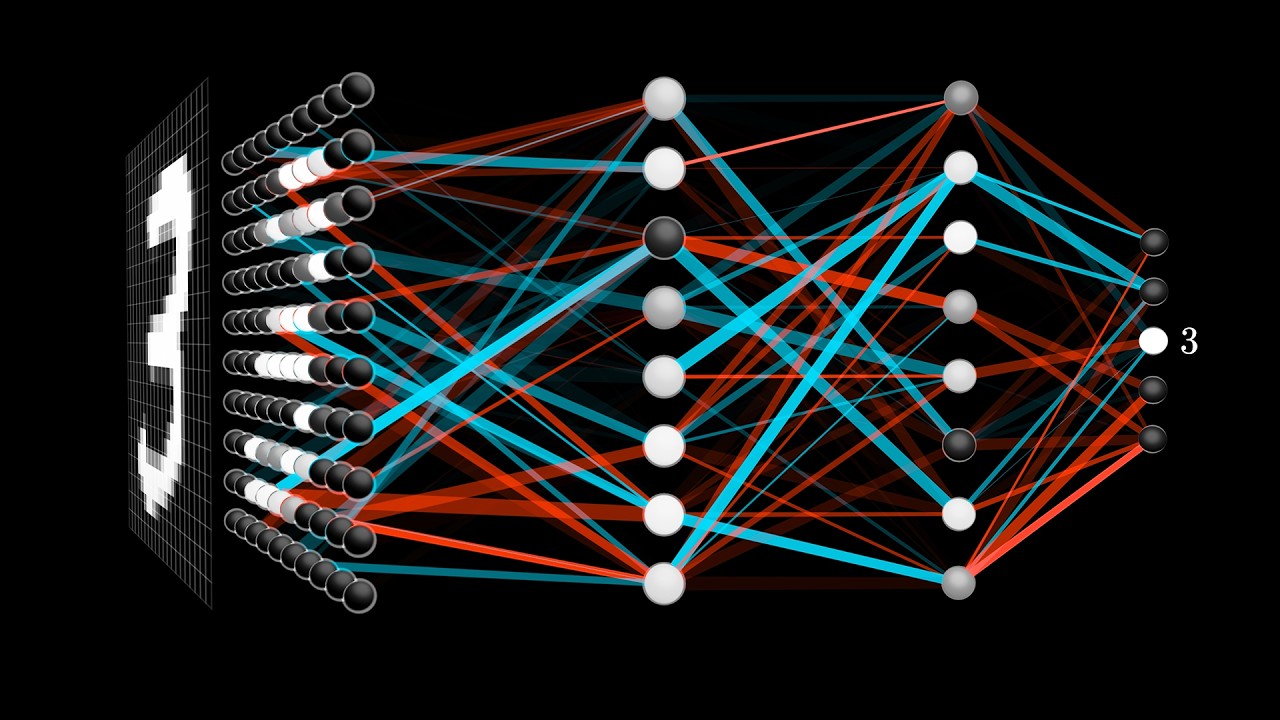
Intro to Large Language Models
A crisp 1-hour primer covering how LLMs are trained, what capabilities emerge at scale, and the security considerations that arise when LLMs act as agents — including tool use, prompt injection, and jailbreaks. Essential grounding for any AI evaluation programme.
#llm#fundamentals#training
Watch on YouTube